Classification in Data Mining Scaler Topics
Classification in data mining is a powerful and versatile technique that enables the categorization and prediction of class labels for various applications. By utilizing a range of classification algorithms, such as Random Forest, Support Vector Machines, and Logistic Regression, data scientists can tackle complex classification tasks and.
DATA MINING TECHNIQUES. What is data mining? by Tanmay Terkhedkar
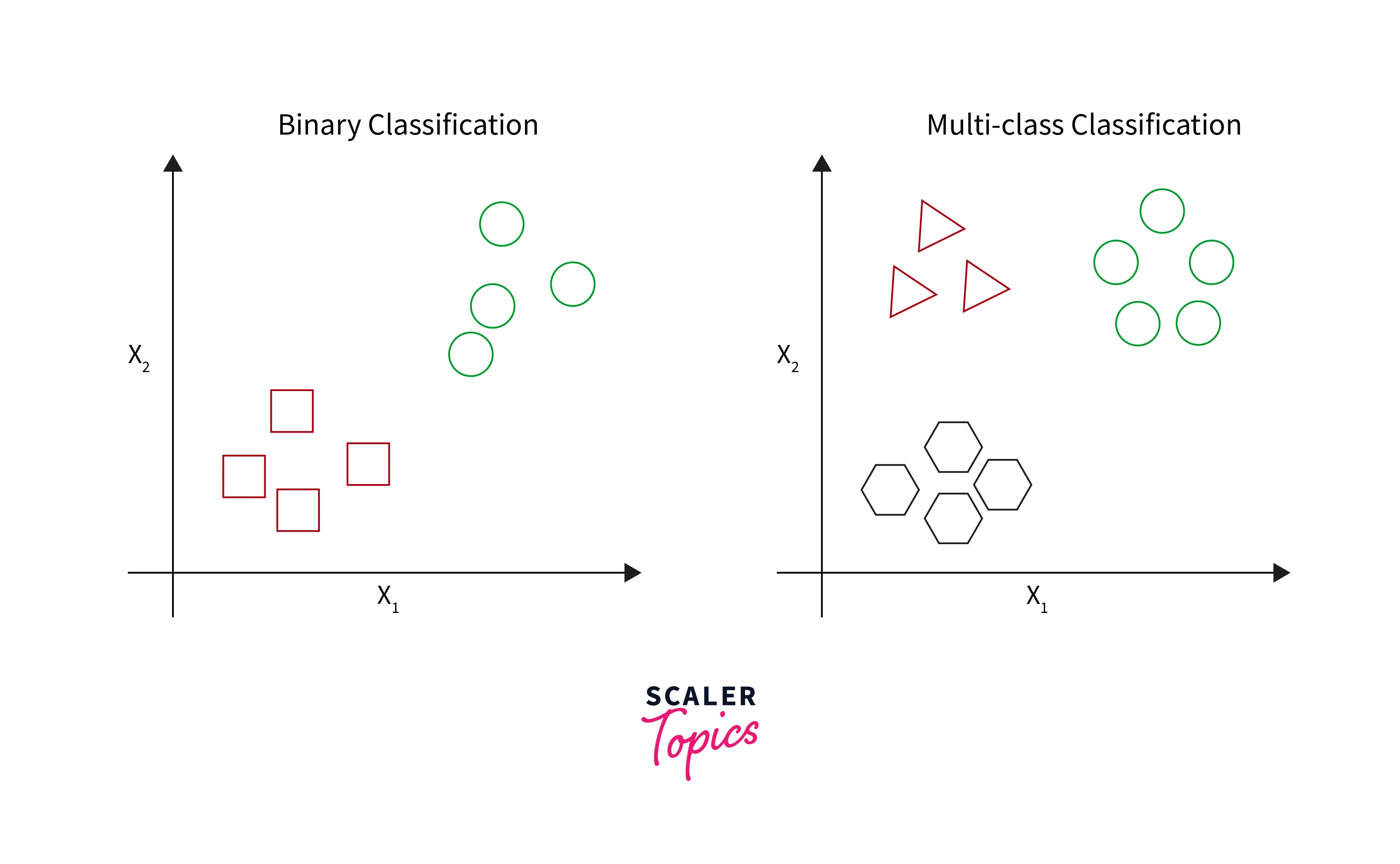
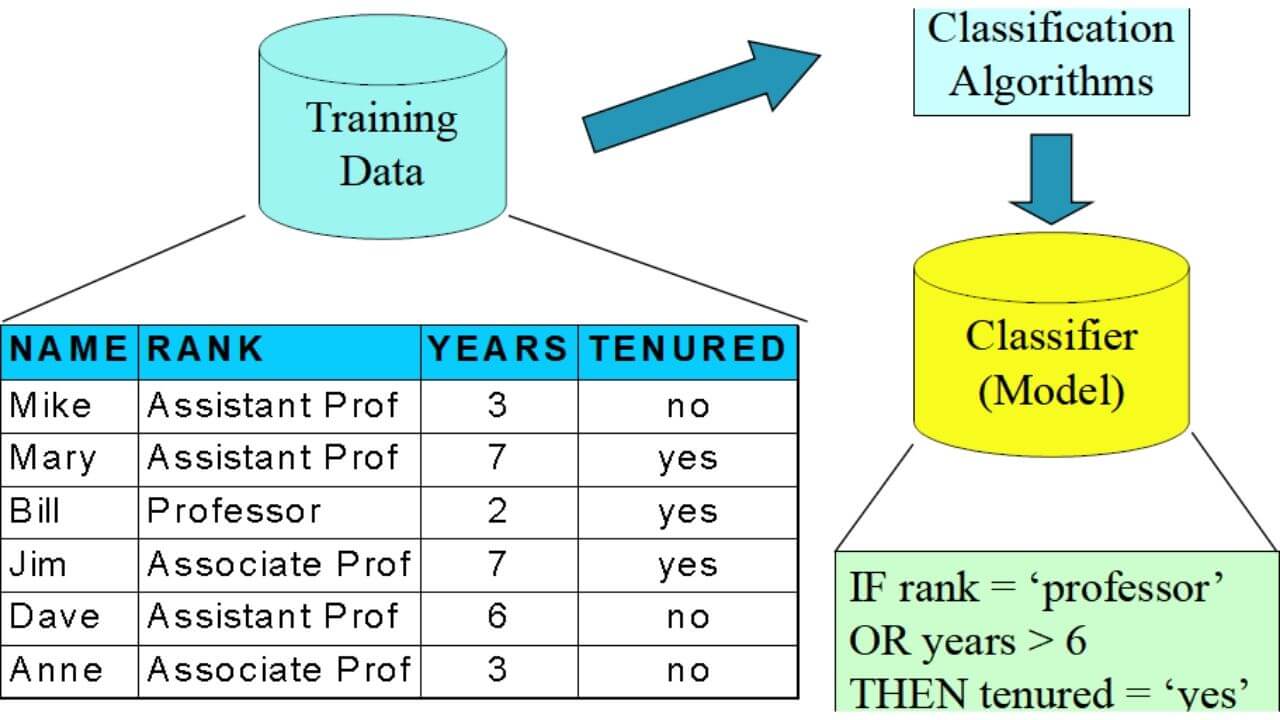
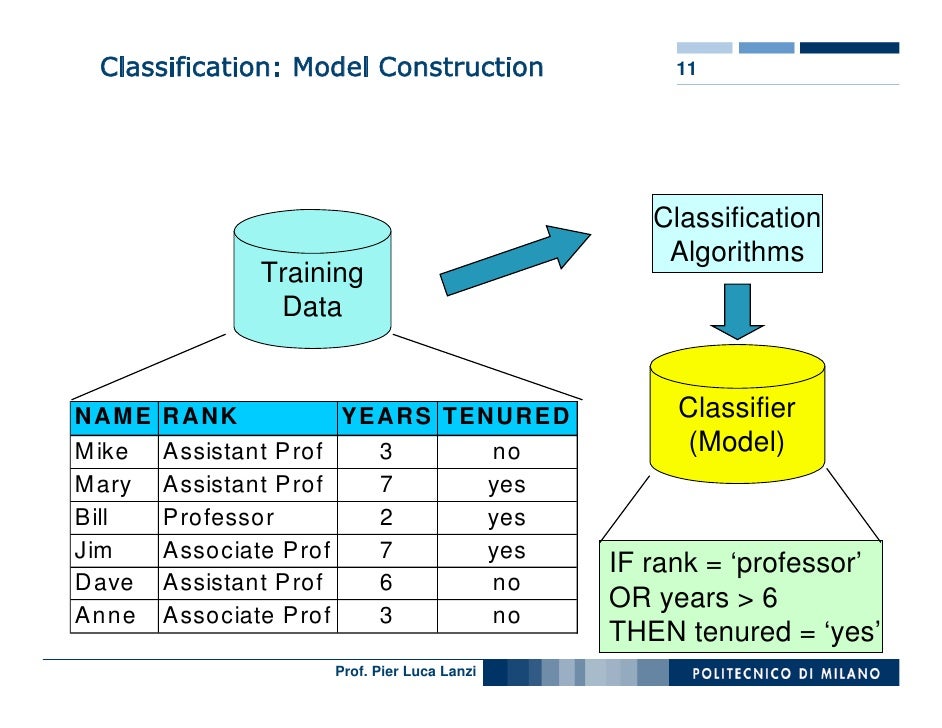
Classification: Definition. Given a collection of records (training set ) - Each record is by characterized by a tuple (x,y), where x is the attribute set and y is the class label. x: attribute, predictor, independent variable, input. y: class, response, dependent variable, output.
PPT Data Mining Concepts and Techniques — Chapter 1 — — Introduction
Classification in data mining is a key technique that involves predicting the class of new data points based on historical data. Classification algorithms learn patterns from labeled data and use these patterns to assign new data points to specific classes. This technique has numerous applications in fields such as image and speech recognition.
Data mining classification process Download Scientific Diagram
Data mining techniques draw from various fields like machine learning (ML) and statistics. Here are a few common data mining techniques: Classification is the task of assigning new data to known or predefined categories. For example, sorting a data set consisting of emails as "spam" or "not spam."

[PDF] Choosing the Right Data Mining Technique Classification of
Classification is a widely used technique in data mining and is applied in a variety of domains, such as email filtering, sentiment analysis, and medical diagnosis. Classification: It is a data analysis task, i.e. the process of finding a model that describes and distinguishes data classes and concepts.

Data Mining Clustering vs. Classification Comparison of the Two
In data mining, classification is an organizational technique used to separate data points into a variety of categories. The data classification process is commonly performed with the help of AI-powered machine learning tools. Modern classification techniques hold a close relationship with machine learning. Elements and variables in a data set.

Data mining classification process. Download Scientific Diagram
Classification in data mining is a common technique that separates data points into different classes. It allows you to organize data sets of all sorts, including complex and large datasets as well as small and simple ones. It primarily involves using algorithms that you can easily modify to improve the data quality.
Classification In Data Mining Various Methods In Classification
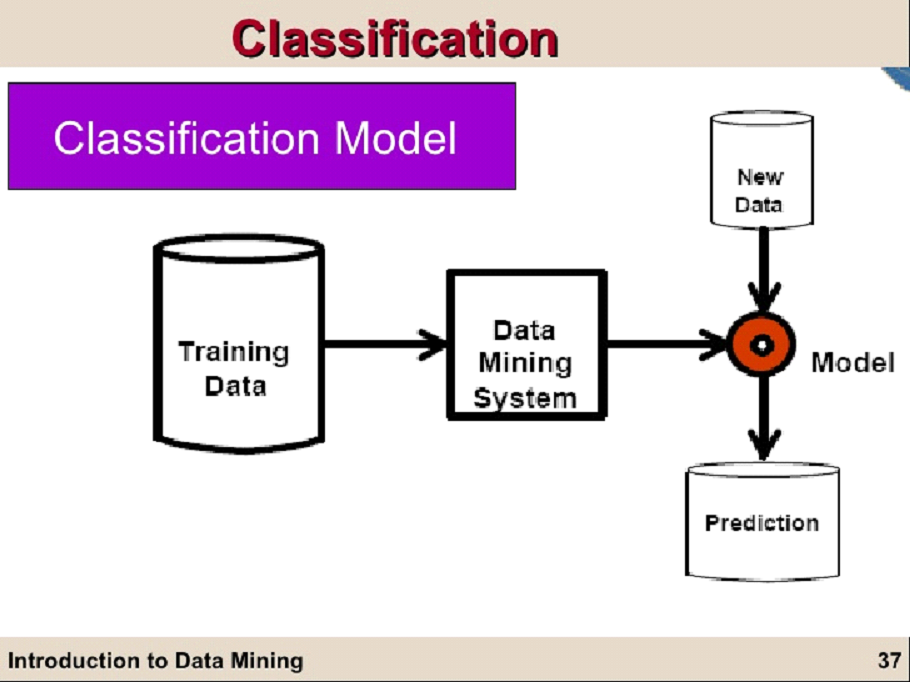
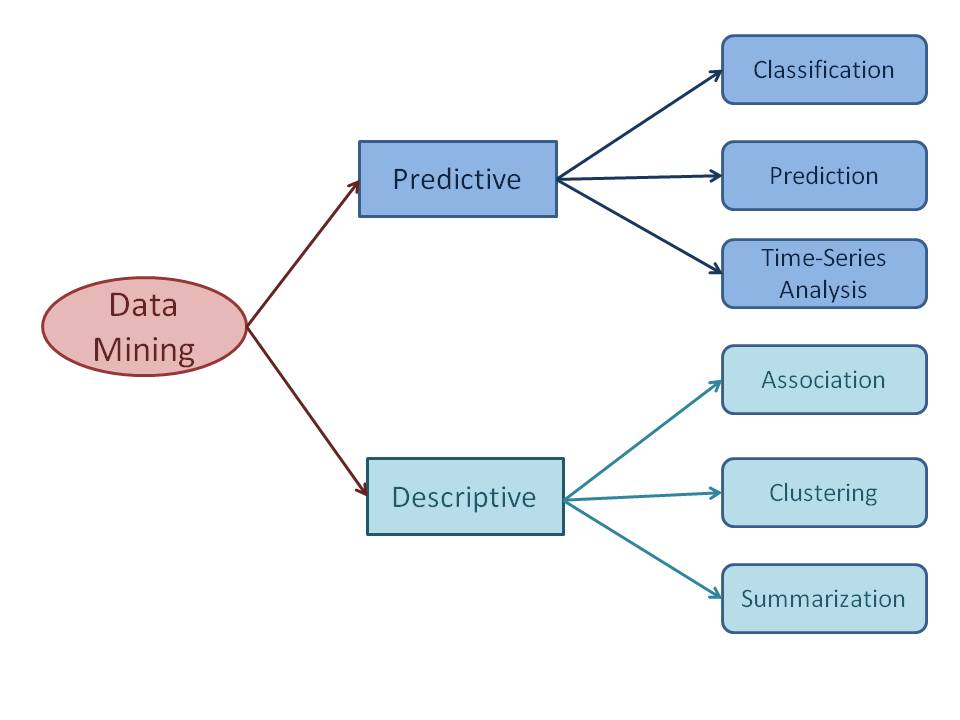
Data Mining - Classification & Prediction. There are two forms of data analysis that can be used for extracting models describing important classes or to predict future data trends. These two forms are as follows −. Classification models predict categorical class labels; and prediction models predict continuous valued functions.
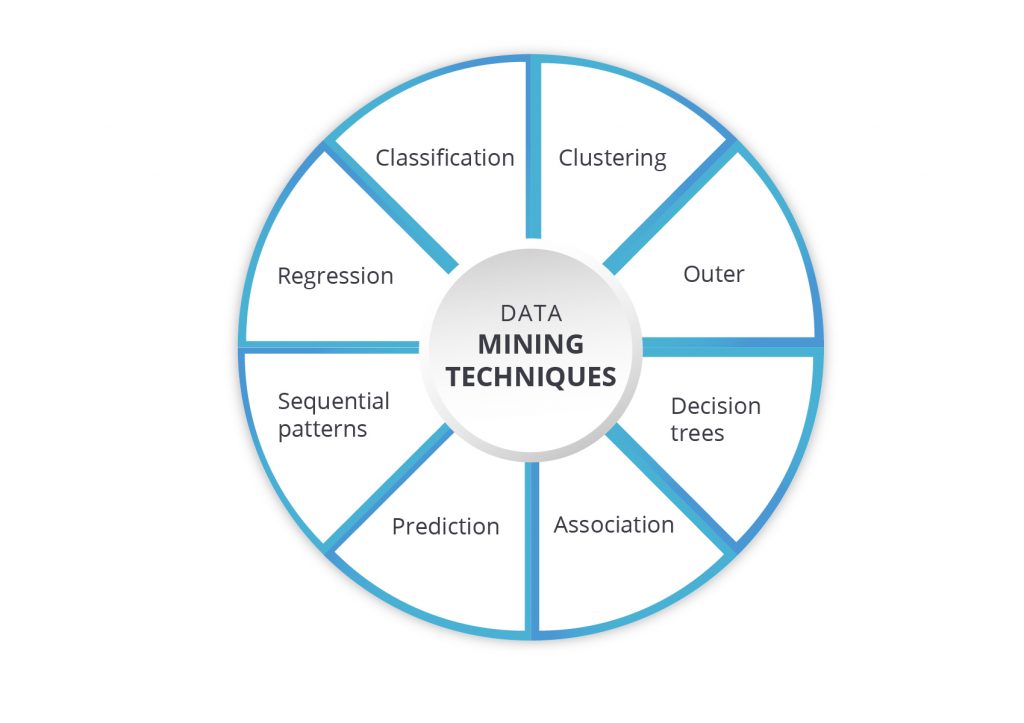
Alternative Spaces Blog 8 Data Mining Techniques You Must Learn To
SVM is another classification techniques in Data Mining. SVM stands for Support Vector Machine and is a supervised Machine Learning technique for classification, regression, and anomaly detection. Classification Techniques in Data Mining such as SVMs work by determining the optimum hyperplane for dividing a dataset into two classes.
Data Mining Tasks Data Mining tutorial by Wideskills
Data mining, also known as knowledge discovery in data (KDD), is the process of uncovering patterns and other valuable information from large data sets.. They also classify and cluster data through classification and regression methods, and identify outliers for use cases, like spam detection. Data mining usually consists of four main steps.
Machine Learning and Data Mining 10 Introduction to Classification
Both classification and clustering are common techniques for performing data mining on datasets. While a skillful data scientist is proficient in both, they're not however equally suitable for solving all problems.As a consequence, it's therefore important to understand their specific advantages and limitations.

Classification Algorithms Explained in 30 Minutes
Data mining is the process of extracting knowledge or insights from large amounts of data using various statistical and computational techniques. The data can be structured, semi-structured or unstructured, and can be stored in various forms such as databases, data warehouses, and data lakes. The primary goal of data mining is to discover.
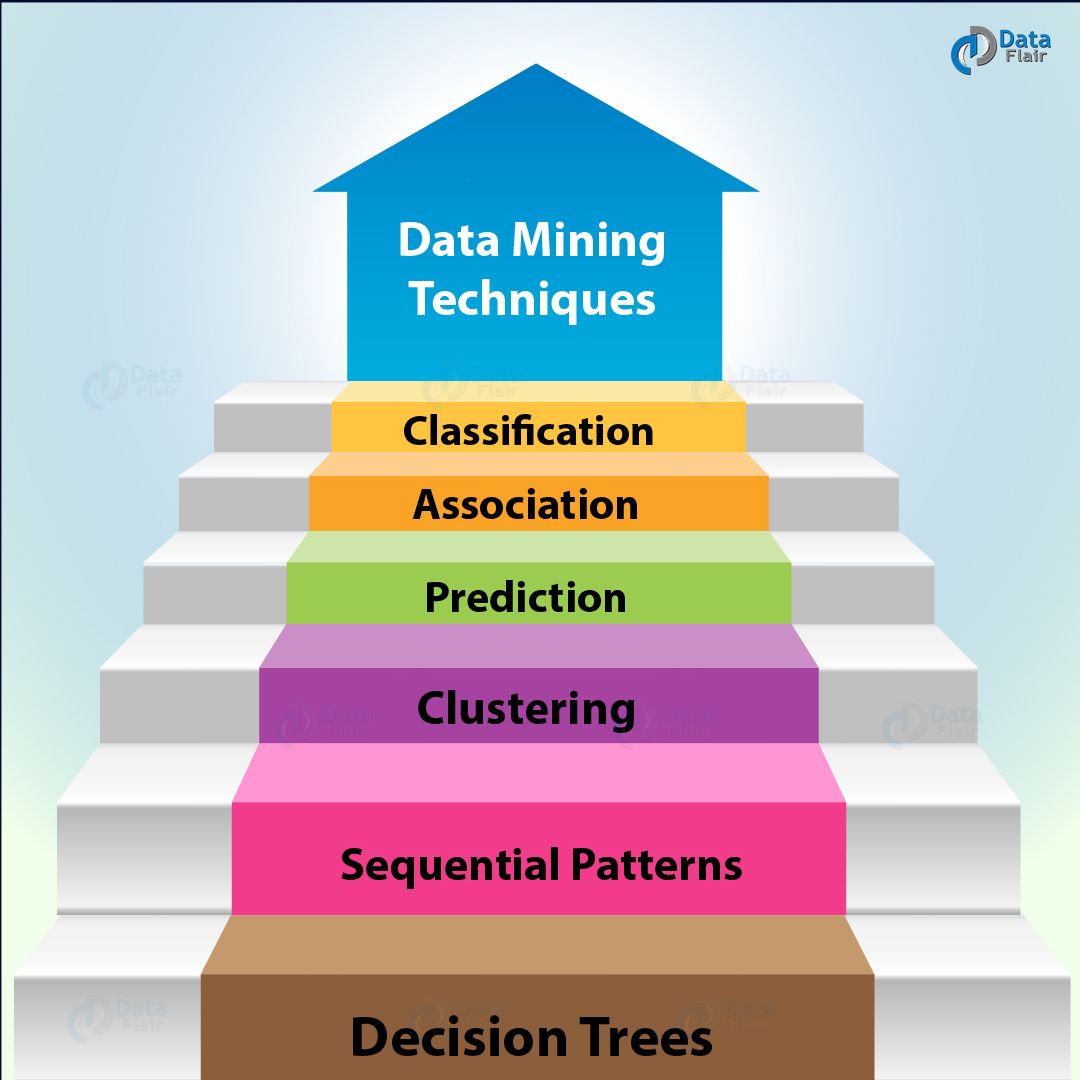
Data Mining Techniques 6 Crucial Techniques in Data Mining DataFlair
These two forms are as follows: Classification. Prediction. We use classification and prediction to extract a model, representing the data classes to predict future data trends. Classification predicts the categorical labels of data with the prediction models. This analysis provides us with the best understanding of the data at a large scale.
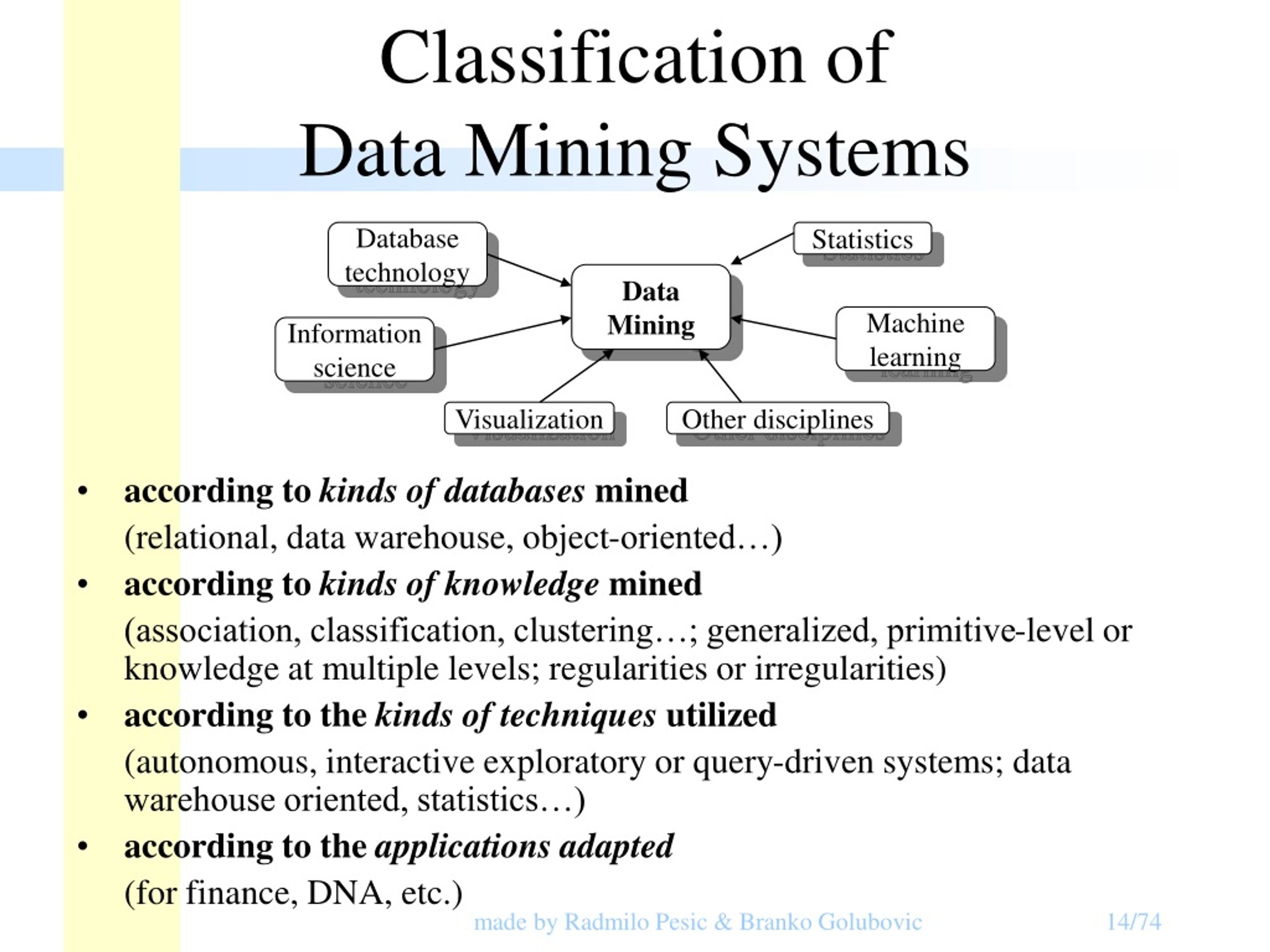
PPT Data Mining PowerPoint Presentation, free download ID8897864
Data Mining Classification helps businesses make informed decisions and also analyze huge amounts of enterprise data. Data Mining Classification helps financial institutions to help defaulters, loan seekers, and other aspects. What are the Disadvantages of Data Mining Classification? Data Mining done through Data Analytics tools is a complex.

PPT Data Mining Classification and Prediction PowerPoint
Classification in data mining is a common technique for dividing data points into different classes. It allows you to manage all types of datasets, including complex and large datasets, as well as small and simple ones.
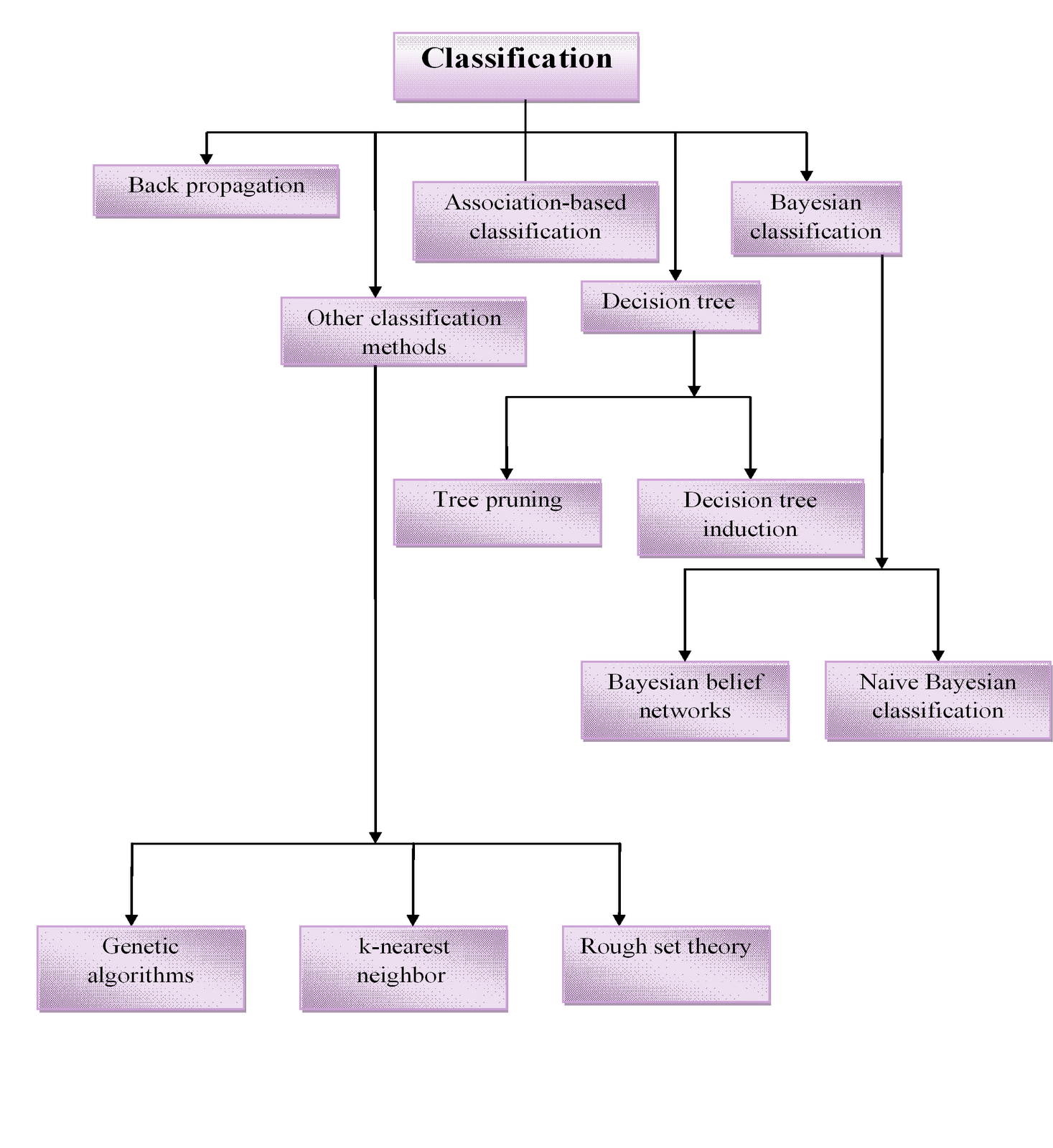
Data Mining Classification Methods
Classification techniques support data analysis and outcomes prediction. Classification is a data-mining technique that assigns categories to a collection of data to aid in more accurate predictions and analysis. Classification is one of several methods intended to make the analysis of very large datasets effective.