Data mining classification process Download Scientific Diagram
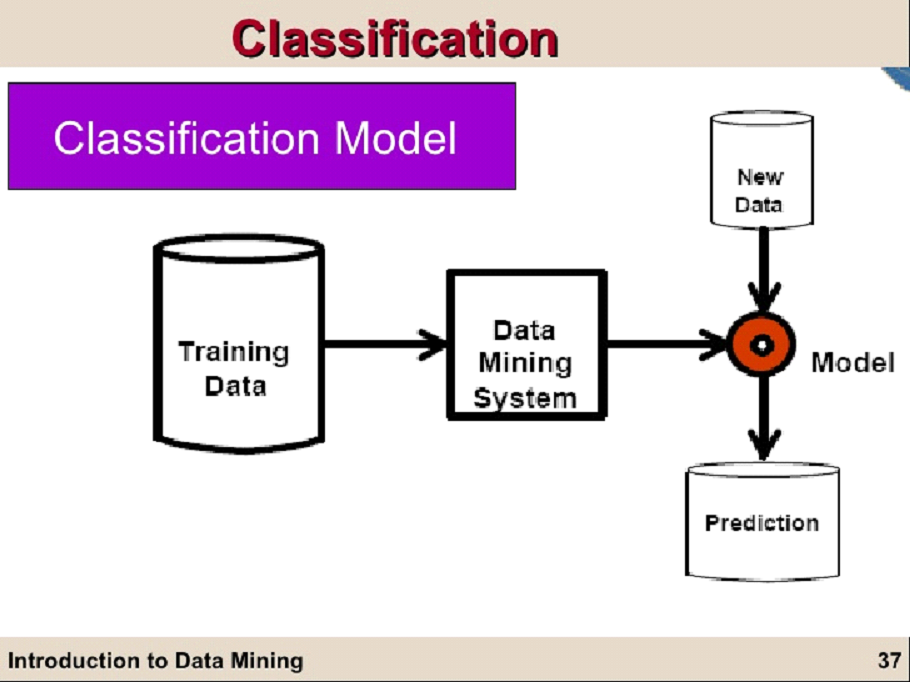
Step 1: Learning Phase. This phase of Data Mining Classification mainly deals with the construction of the Classification model based on different algorithms available. This step requires a training set for the model to learn. The trained model gives accurate results based on the target dataset.
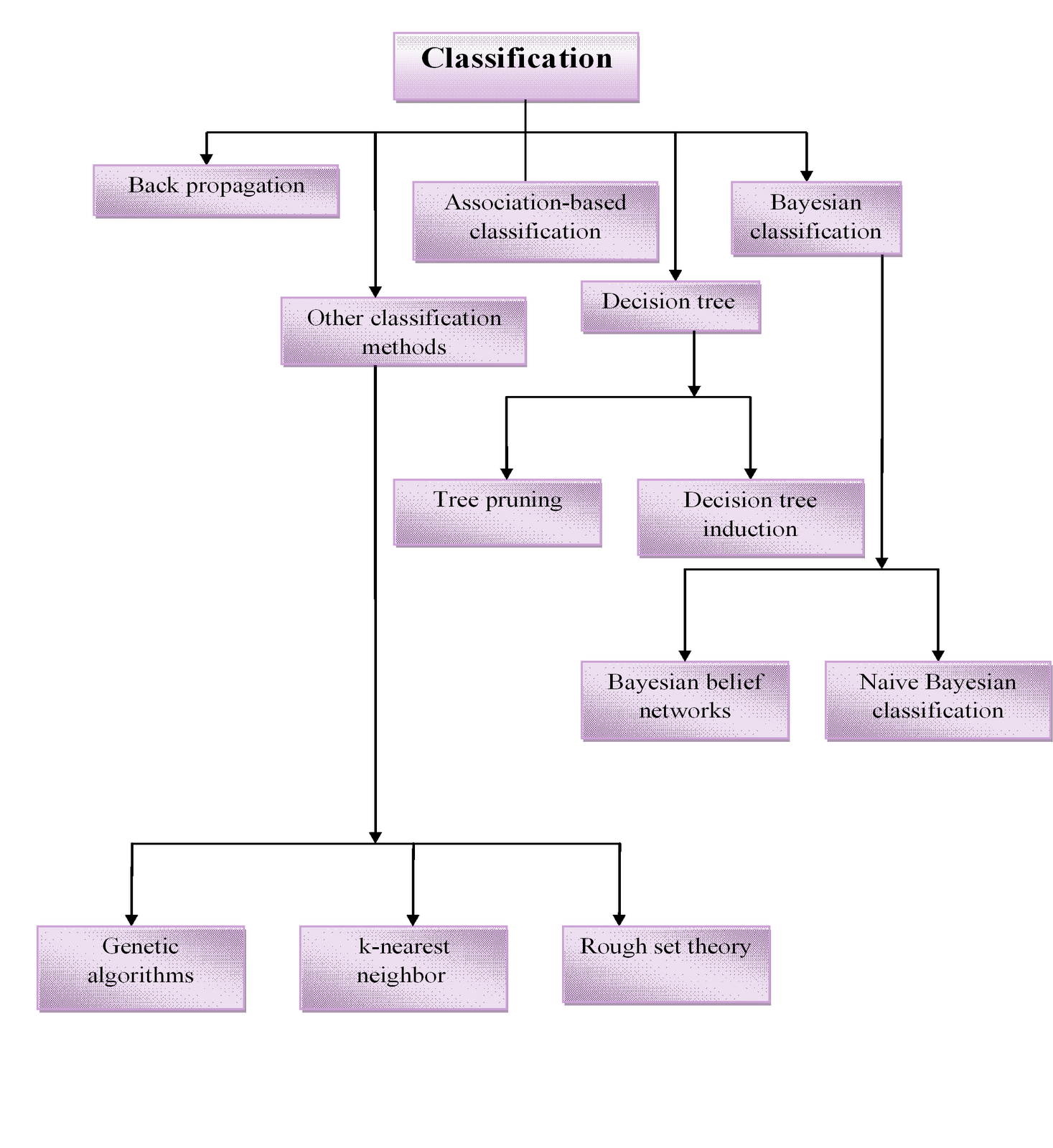
Data Mining Classification Methods
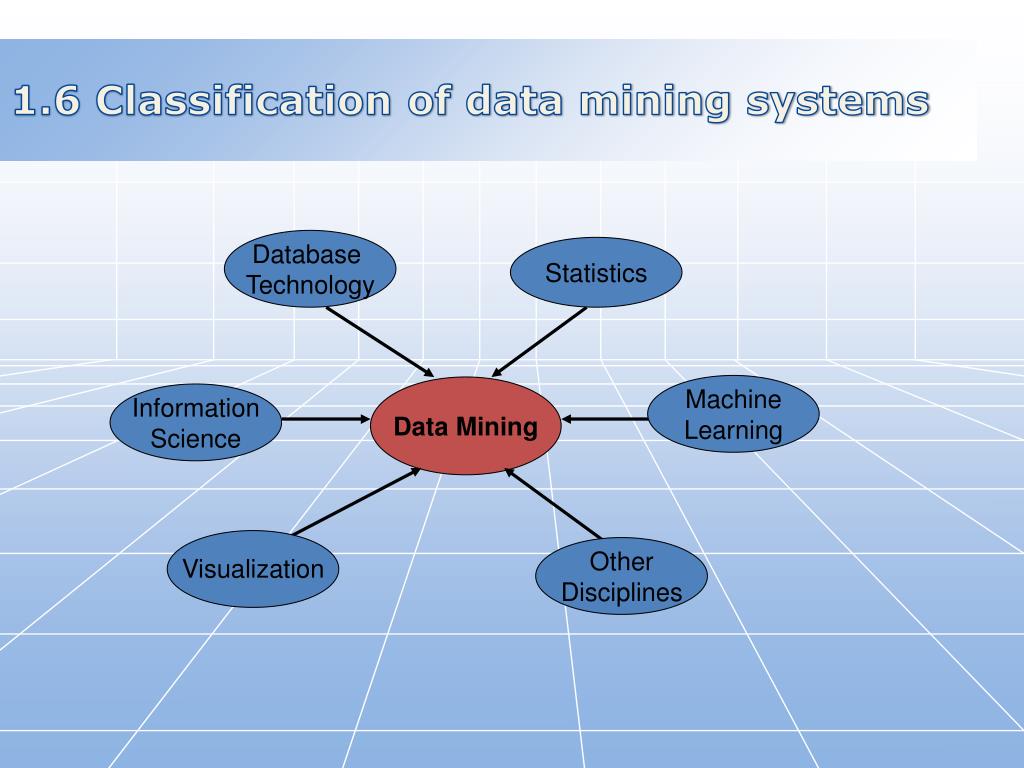
Data Mining Classification as Per the Type of Knowledge Mined. Classification of data mining systems can occur relevant to the form of knowledge mined. This implies that the type is reliable on a few functionalities, namely: Correlation And Association Analysis. Classification and Prediction in data mining. Characterization.
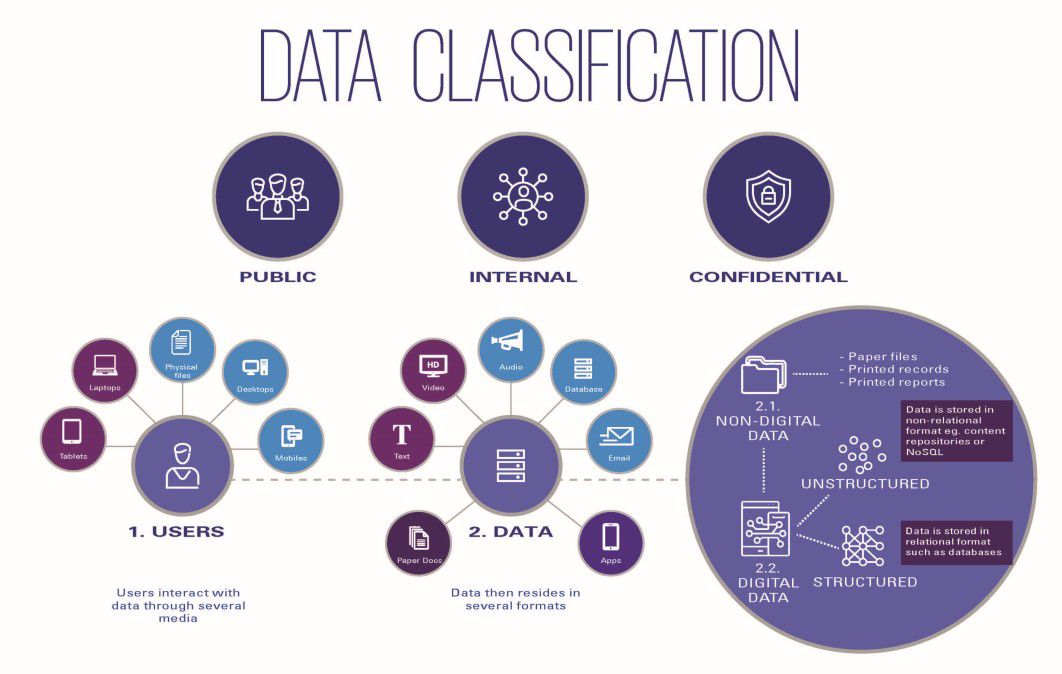
Three steps to achieve successful data classification KPMG Oman
Classification is a data mining technique in the machine learning domain. Various algorithms such as K-nearest neighbor, support vector machines, random forest, logistic regression, and decision trees are used to solve the classification problem. Out of them, logistic regression and decision trees are perhaps the most used classification.
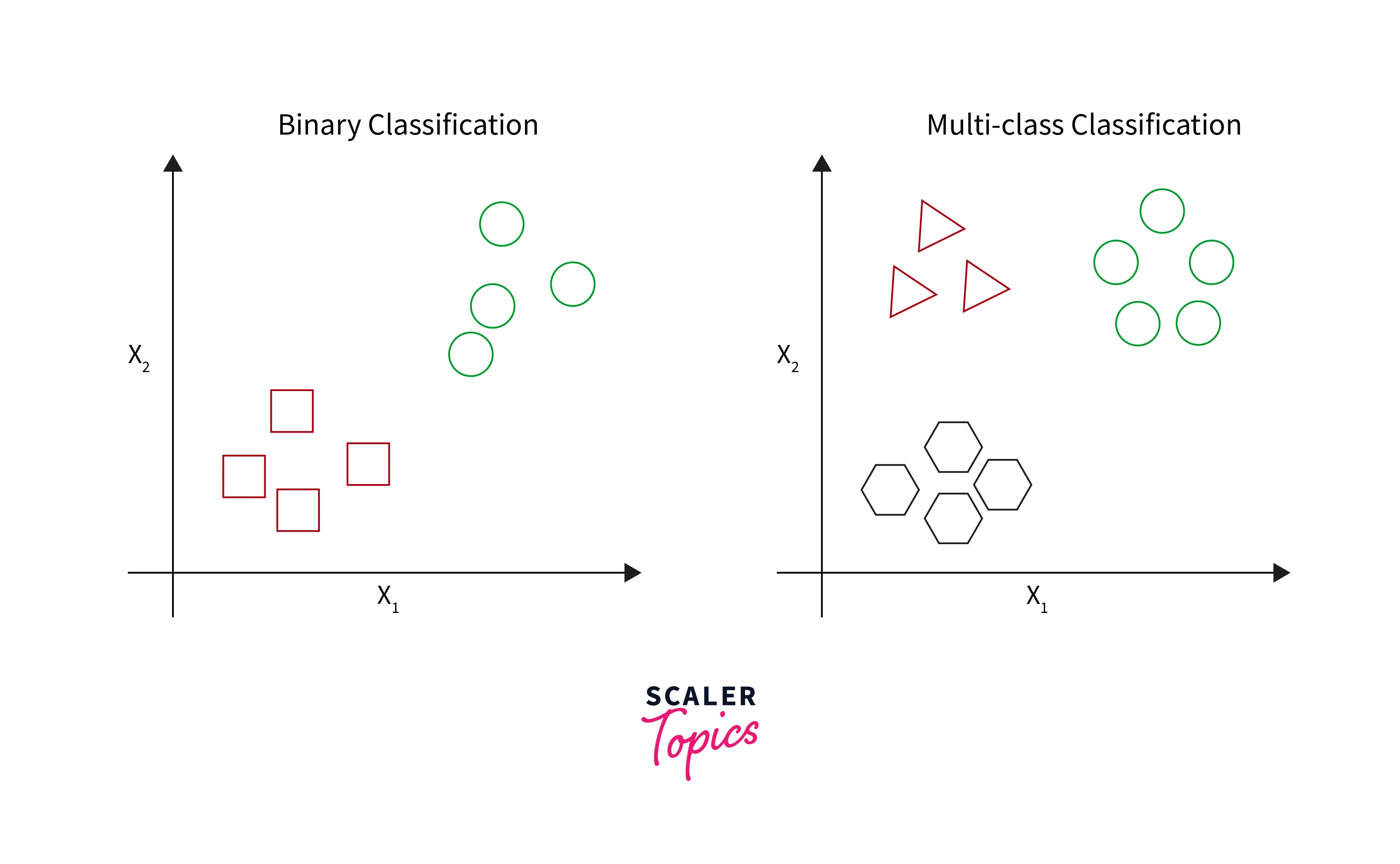
Classification in Data Mining Scaler Topics
Classification in data mining is a common technique that separates data points into different classes. It allows you to organize data sets of all sorts, including complex and large datasets as well as small and simple ones. It primarily involves using algorithms that you can easily modify to improve the data quality.
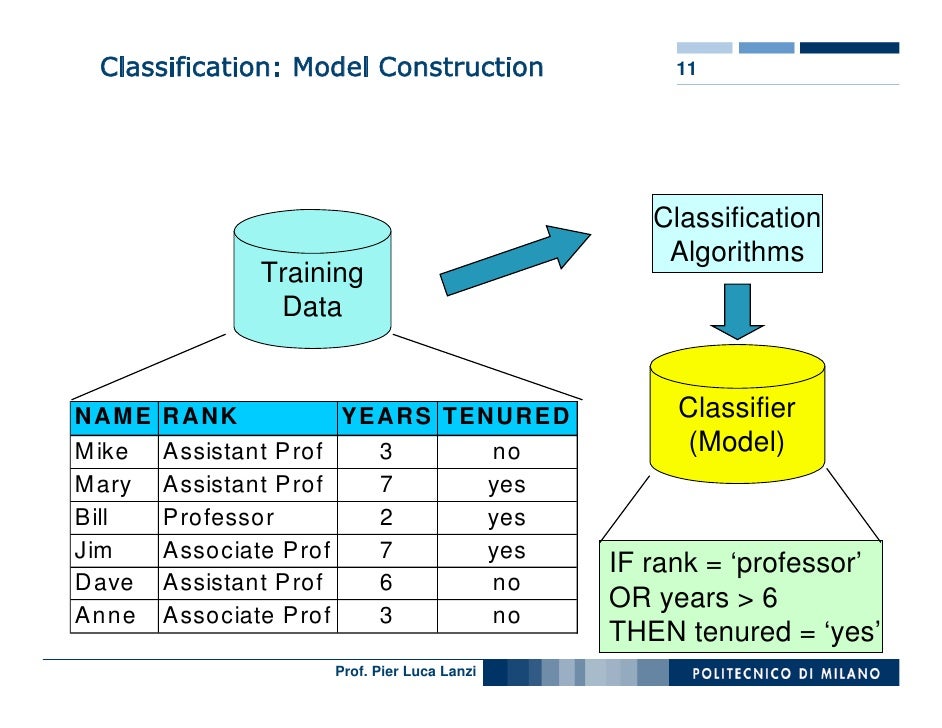
Machine Learning and Data Mining 10 Introduction to Classification
A sample data for the vertebrate classification problem. Vertebrate Body Skin Gives Aquatic Aerial Has Hiber- Class Name Temperature Cover Birth Creature Creature Legs nates Label human warm-blooded hair yes no no yes no mammal python cold-blooded scales no no no no yes reptile salmon cold-blooded scales no yes no no no fish
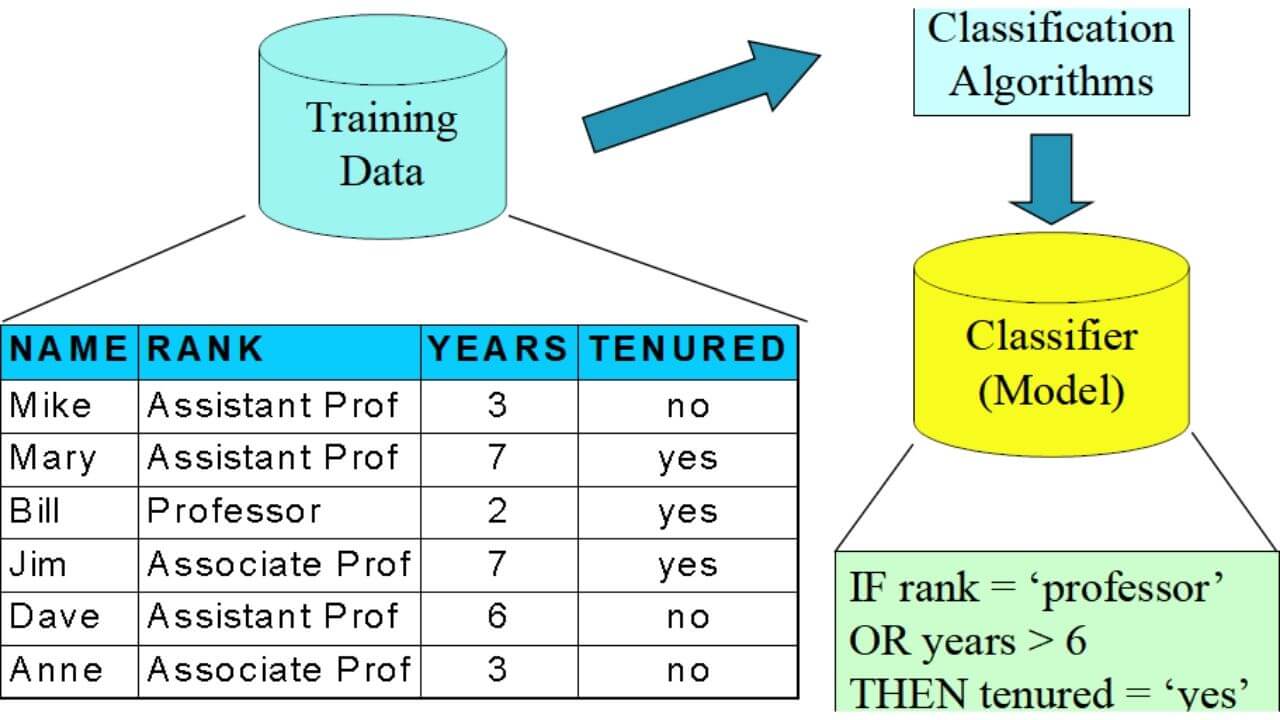
Classification In Data Mining Various Methods In Classification
Classification: Definition. Given a collection of records (training set ) - Each record is by characterized by a tuple (x,y), where x is the attribute set and y is the class label. x: attribute, predictor, independent variable, input. y: class, response, dependent variable, output.
PPT Data Mining Concepts and Techniques — Chapter 1 — — Introduction
with D_1 and D_2 subsets of D, 𝑝_𝑗 the probability of samples belonging to class 𝑗 at a given node, and 𝑐 the number of classes.The lower the Gini Impurity, the higher is the homogeneity of the node. The Gini Impurity of a pure node is zero. To split a decision tree using Gini Impurity, the following steps need to be performed.
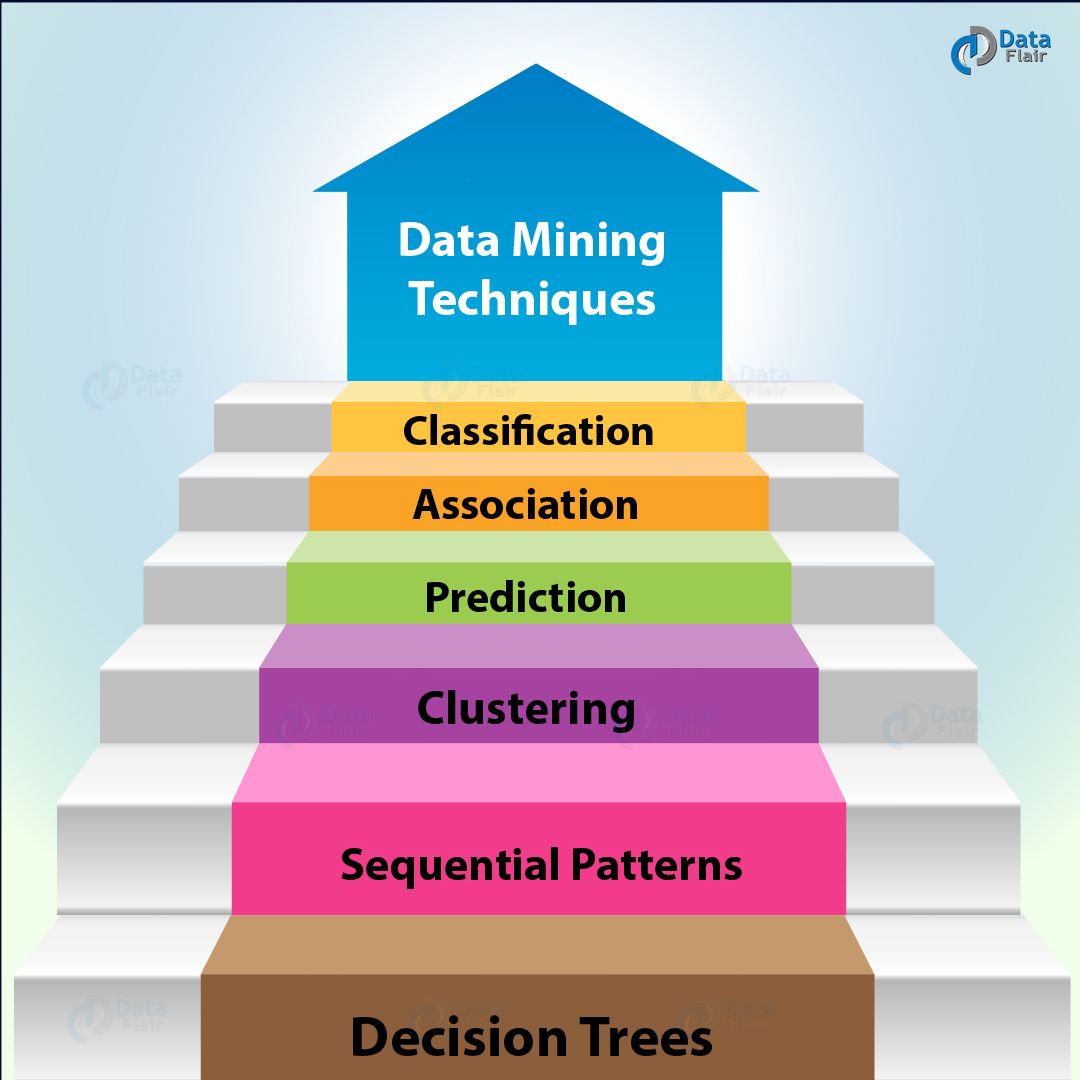
Data Mining Techniques 6 Crucial Techniques in Data Mining DataFlair
Classification in data mining is a powerful and versatile technique that enables the categorization and prediction of class labels for various applications. By utilizing a range of classification algorithms, such as Random Forest, Support Vector Machines, and Logistic Regression, data scientists can tackle complex classification tasks and.

ClassificationBased Approaches in Data Mining
Classification-Based Approaches in Data Mining. Classification is that the processing of finding a group of models (or functions) that describe and distinguish data classes or concepts, for the aim of having the ability to use the model to predict the category of objects whose class label is unknown. The determined model depends on the.
DATA MINING TECHNIQUES. What is data mining? by Tanmay Terkhedkar
Classification in data mining is a key technique that involves predicting the class of new data points based on historical data. Classification algorithms learn patterns from labeled data and use these patterns to assign new data points to specific classes. This technique has numerous applications in fields such as image and speech recognition.
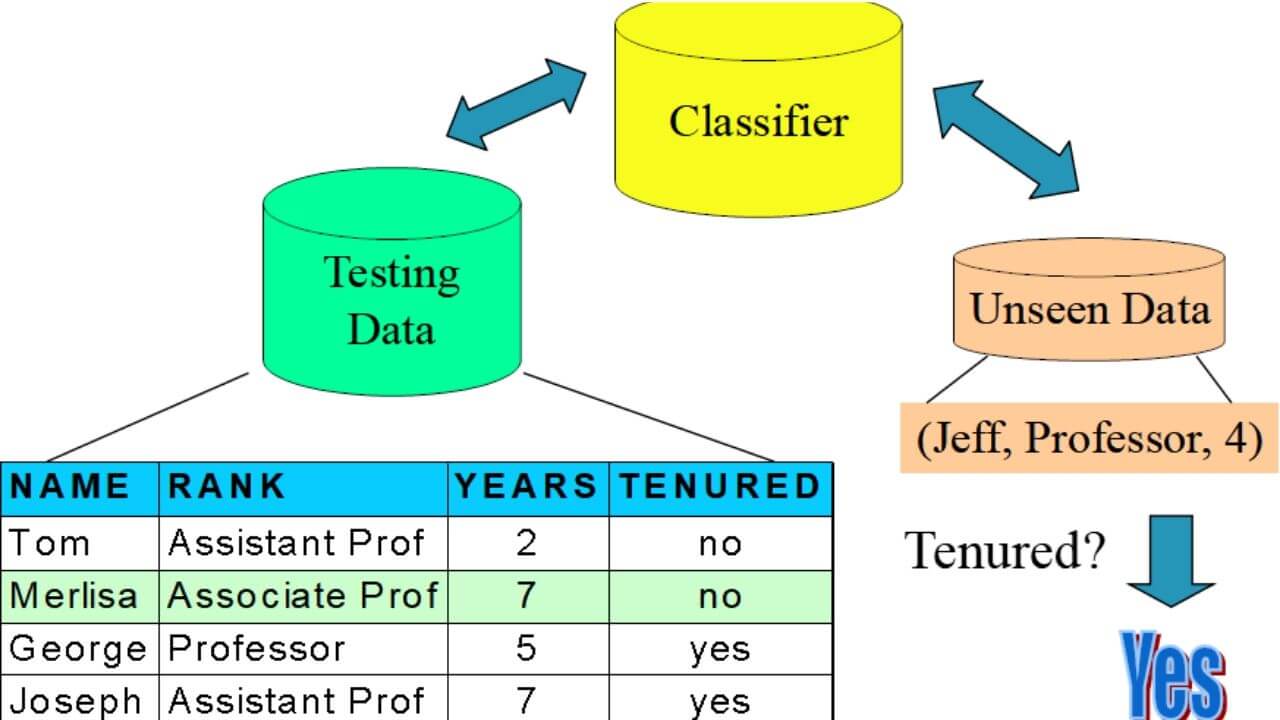
Classification In Data Mining Various Methods In Classification
Data mining is the process of discovering and extracting hidden patterns from different types of data to help decision-makers make decisions. Associative classification is a common classification learning method in data mining, which applies association rule detection methods and classification to create classification models.
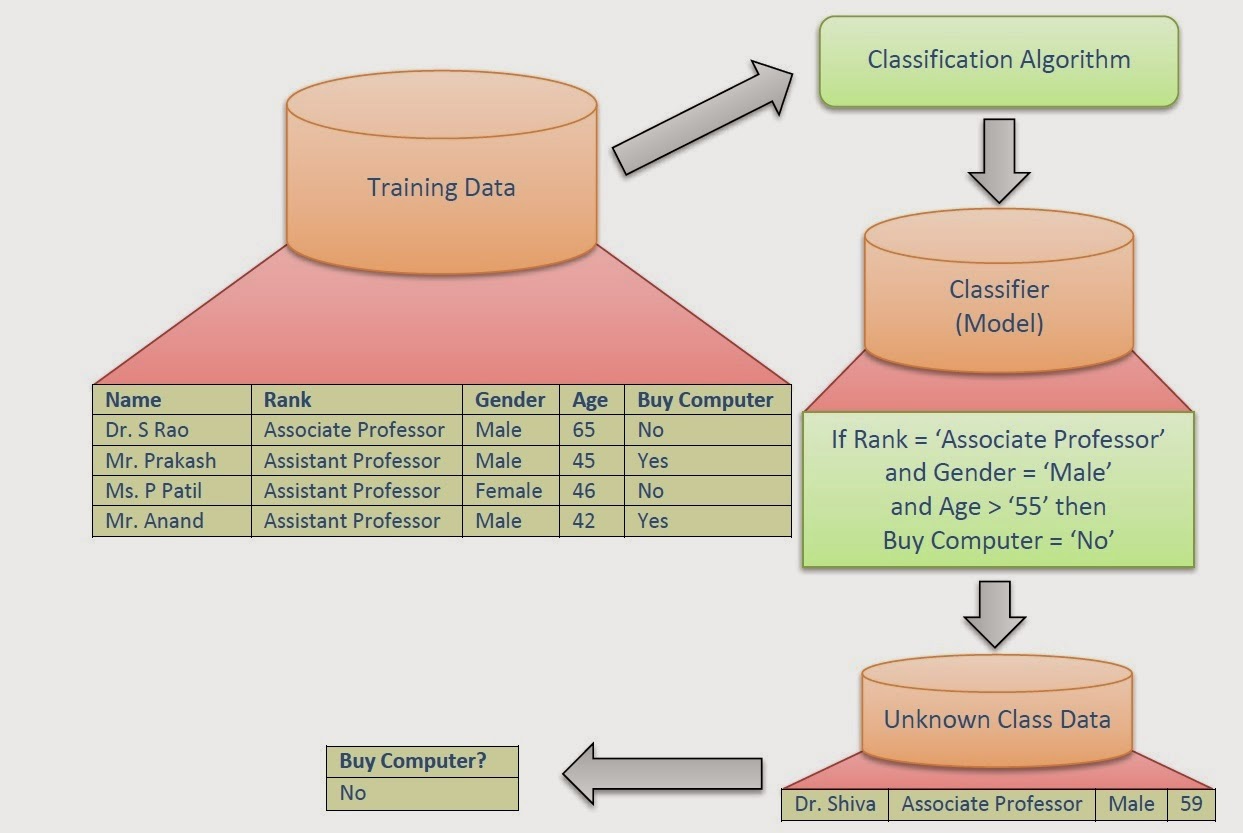
Data Mining Classification Sone Valley
Classification is a widely used technique in data mining and is applied in a variety of domains, such as email filtering, sentiment analysis, and medical diagnosis. Classification: It is a data analysis task, i.e. the process of finding a model that describes and distinguishes data classes and concepts. Classification is the problem of.

Working principle of data mining classification process. Download
There are many different classification algorithms used in data mining, each with its own strengths and weaknesses. Some of the most popular algorithms include decision trees, logistic regression, naive Bayes classification, k-nearest neighbors, and support vector machines. The choice of which classification algorithm to use depends on the.
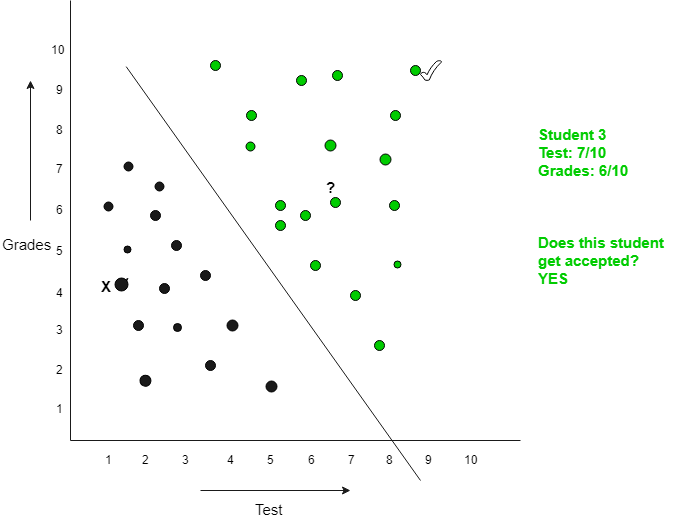
Basic Concept of Classification (Data Mining)
Data mining techniques draw from various fields like machine learning (ML) and statistics. Here are a few common data mining techniques: Classification is the task of assigning new data to known or predefined categories. For example, sorting a data set consisting of emails as "spam" or "not spam."

Classification In Data Mining slidesharedocs
Classification techniques support data analysis and outcomes prediction. Classification is a data-mining technique that assigns categories to a collection of data to aid in more accurate predictions and analysis. Classification is one of several methods intended to make the analysis of very large datasets effective.
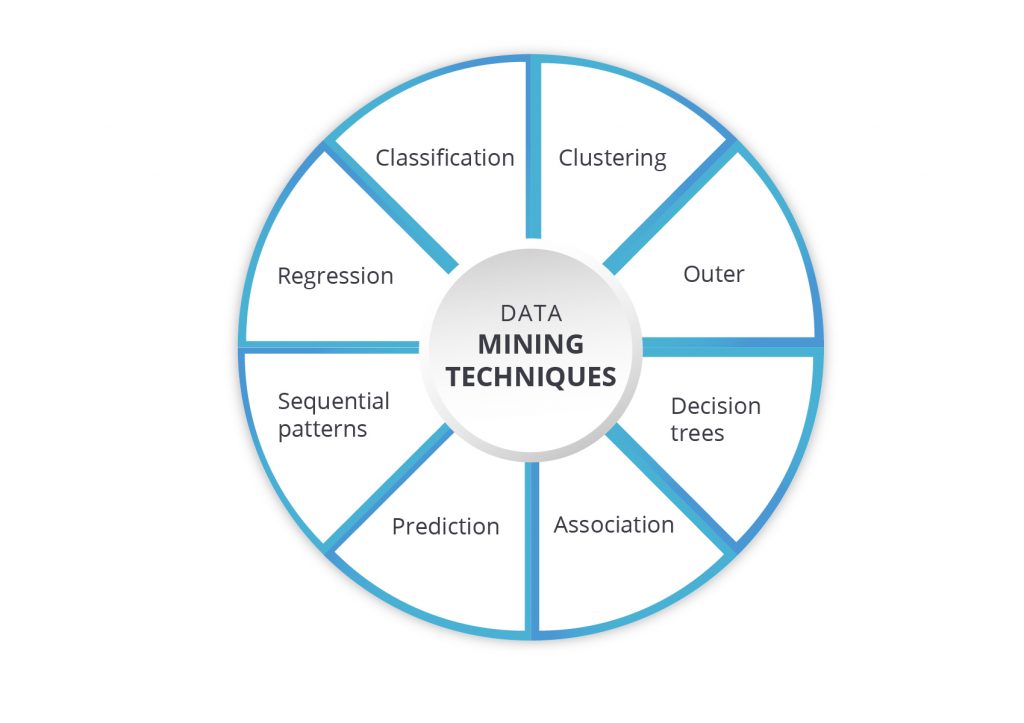
Alternative Spaces Blog 8 Data Mining Techniques You Must Learn To
Classification in data mining is definitely an expanding field of study. Classification plays an integral role in the context of mining techniques. As suggested by its name, this is a process where you classify data. And, many decisions need to be made to bring the data together. Often, it depends on a set of input variables.
